Model Performance Concepts
- Model performance concepts explain how well a machine learning model generalizes to unseen data while avoiding overfitting and underfitting.
Bias vs Variance
These are two sources of prediction error in machine learning models.
Total Error=Bias2+Variance+Irreducible Error\text{Total Error} = \text{Bias}^2 + \text{Variance} + \text{Irreducible Error}Total Error=Bias2+Variance+Irreducible Error
Bias
Bias is error due to overly simplistic assumptions in the model
High bias → model cannot capture patterns in data → underfitting
Example: Using a linear model to predict a highly non-linear relationship
Model prediction is consistently far from actual values
Low training accuracy
Variance
Variance is error due to sensitivity to training data
High variance → model captures noise in training data → overfitting
Example: Using a high-degree polynomial for small dataset
Training accuracy → very high
Test accuracy → very low (fails on new data)
Overfitting
Model fits training data too closely, capturing both patterns and noise
Performs well on training data but poorly on unseen data
Causes
Very complex model
Too many features
Insufficient training data
Solutions
Simplify model
Reduce features
Use regularization (L1, L2)
Get more training data
Cross-validation
Underfitting
Model fails to capture underlying patterns in data
Performs poorly on training and test data
Causes
Very simple model
Not enough features
High bias algorithm
Solutions
Increase model complexity
Add relevant features
Reduce regularization
Bias-Variance Tradeoff
Visual Example (Python)
Bias–Variance Tradeoff Example in Python using Polynomial Regression
This Python example demonstrates the concept of the Bias–Variance Tradeoff using Polynomial Regression. The code generates sample data and fits models with different polynomial degrees (1, 3, and 15) to illustrate underfitting, a good fit, and overfitting. The results are visualized using Matplotlib to show how model complexity affects the prediction curve.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# Generate data
np.random.seed(42)
X = np.linspace(0, 10, 20).reshape(-1,1)
y = np.sin(X) + 0.2*np.random.randn(20,1)
# Fit models of different complexity
degrees = [1, 3, 15] # Linear=underfit, 3=good, 15=overfit
plt.scatter(X, y, color='black', label='Data')
X_plot = np.linspace(0, 10, 100).reshape(-1,1)
for d in degrees:
poly = PolynomialFeatures(degree=d)
X_poly = poly.fit_transform(X)
model = LinearRegression()
model.fit(X_poly, y)
y_plot = model.predict(poly.transform(X_plot))
plt.plot(X_plot, y_plot, label=f'Degree {d}')
plt.legend()
plt.title("Bias-Variance Example")
plt.show()- Output:
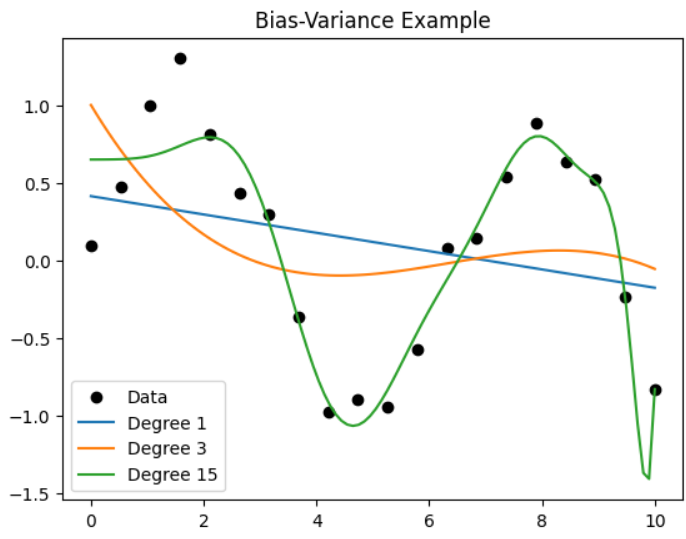
Degree 1 → High Bias (Underfitting)
Degree 3 → Balanced (Good fit)
Degree 15 → High Variance (Overfitting)
Summary Table