Decision Tree Regression
- This module explains Decision Tree Regression, covering tree structure, splitting criteria, information gain, and understanding overfitting in tree-based models.
Tree Structure
A Decision Tree has three main components:
Root Node
The first node where data is split.
Internal Nodes
Decision points based on feature values.
Leaf Nodes
Final output values (predicted value).
Example (House Price Prediction)
Features:
Area
Bedrooms
Tree Structure Example:
Is Area <= 1200?
Yes → Price = 200000
No
Is Bedrooms <= 3?
Yes → Price = 300000
No → Price = 400000
The model divides the dataset into regions and predicts the average value in each region.
Splitting Criteria
In Decision Tree Regression, splits are chosen based on reducing error.
The most common splitting method is:
Mean Squared Error (MSE)
The algorithm:
Tries different split points
Calculates MSE for each split
Chooses the split with lowest MSE
Goal of Splitting
Reduce variance inside each node.
After splitting:
Data inside each region becomes more similar
Prediction becomes more accurate
Information Gain
Information Gain measures how much uncertainty is reduced after a split.
Important:
Information Gain is mainly used in classification trees
In regression trees, we usually use variance reduction or MSE reduction
Formula (Conceptual)
Information Gain=Parent Error−Weighted Child ErrorInformation\ Gain = Parent\ Error - Weighted\ Child\ ErrorInformation Gain=Parent Error−Weighted Child Error
If the error reduces significantly → good split
If error barely changes → bad splitOverfitting in Decision Trees
Decision Trees can easily overfit because:
They can grow very deep
They can memorize training data
They create very complex rules
Signs of Overfitting
Training score = Very high
Testing score = Low
Tree depth is very large
How to Prevent Overfitting
Limit max_depth
Set minimum samples per leaf
Pruning
Use Random Forest
Example: Predict House Price Based on Area
Decision Tree Regression for House Price Prediction
This code demonstrates how to use a Decision Tree Regressor in Python to predict house prices based on area. The model is trained on sample data, makes predictions for new values, and visualizes the relationship between area and price using a graph.
# Step 1: Import Libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
# Step 2: Create Dataset
X = np.array([500, 800, 1000, 1200, 1500, 1800]).reshape(-1, 1)
y = np.array([100000, 150000, 200000, 230000, 300000, 350000])
# Step 3: Create Model
model = DecisionTreeRegressor(max_depth=2)
# Step 4: Train Model
model.fit(X, y)
# Step 5: Predict
X_test = np.linspace(500, 1800, 100).reshape(-1, 1)
y_pred = model.predict(X_test)
# Step 6: Plot
plt.scatter(X, y)
plt.plot(X_test, y_pred)
plt.xlabel("Area")
plt.ylabel("Price")
plt.title("Decision Tree Regression")
plt.show()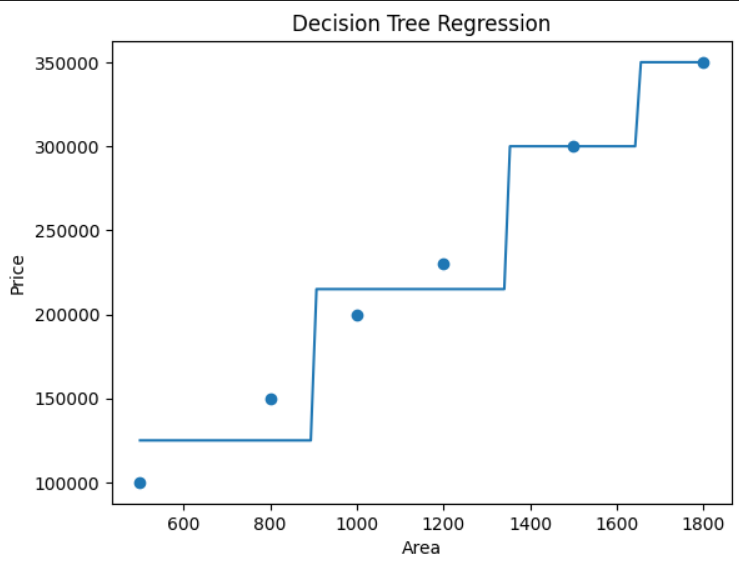
What You Will Notice in Graph
Instead of a smooth line
The prediction looks like steps
Because tree predicts constant value in each region
Model Complexity